

Introdução
Nos últimos anos, ficou difícil passar um dia sem interagir com algum sistema que toma decisões sozinho. Plataformas de streaming, aplicativos de banco, lojas online, serviços de entrega — boa parte do que essas ferramentas fazem de forma automática e aparentemente instantânea não é resultado de regras fixas programadas por um engenheiro. É resultado de um modelo que aprende com dados.
A Netflix sabe o que você quer assistir antes de você decidir. O Spotify monta uma playlist que parece ter sido escolhida por alguém que te conhece há anos. Nada disso é intuição. Por trás de cada uma dessas decisões existe um modelo estatístico treinado com dados reais, capaz de reconhecer padrões e fazer previsões úteis. Isso é, em essência, o que se chama de Machine Learning.
O termo virou expressão corporativa, aparece em apresentações de startup e em manchetes de tecnologia com uma frequência que já cansa. Mas o conceito em si é mais antigo, mais sólido e mais aplicável do que o hype sugere. Segundo pesquisa da McKinsey, 72% das organizações já utilizam inteligência artificial em pelo menos uma função empresarial — e a maior parte dessas aplicações começa exatamente onde toda boa estatística começa: com dados que a empresa já possui, mas ainda não sabe usar.
O que diferencia as organizações que extraem valor real dessa tecnologia das que apenas falam sobre ela não é o acesso a ferramentas sofisticadas: é ir além do uso superficial. Venha entender como um modelo estatístico realmente funciona, onde ele já está gerando resultado concreto e por que tantas empresas ainda deixam esse potencial parado na gaveta.
O que é, de fato, modelagem estatística?
Existe uma confusão comum quando o assunto é Machine Learning: a de que se trata de algo fundamentalmente novo, quase misterioso, distante da estatística tradicional. Na prática, não é bem assim.
Um modelo estatístico é uma representação matemática de uma relação entre variáveis. Dado um conjunto de informações de entrada, como o histórico de compras de um cliente, o comportamento de uma transação financeira ou os dados de temperatura de uma máquina industrial, o modelo aprende a produzir uma saída útil: uma previsão, uma classificação, uma estimativa de risco. O que o Machine Learning adiciona a essa ideia clássica é a capacidade de aprender essa relação diretamente dos dados, sem que alguém precise especificá-la manualmente.
A analogia mais direta é a de um funcionário novo numa empresa. No primeiro dia, ele não sabe nada sobre os clientes, os produtos ou os padrões do negócio. Com o tempo, à medida que acumula experiência e recebe correções, sua capacidade de tomar boas decisões melhora. Um modelo estatístico faz exatamente isso, só que em escala e velocidade que nenhum humano consegue acompanhar.
Esse processo tem um nome técnico: treinamento. O modelo recebe exemplos históricos e ajusta seus parâmetros internos para minimizar os erros nas previsões. À medida que mais dados são apresentados, o erro tende a cair até um ponto em que o modelo aprendeu o suficiente para generalizar bem para situações que nunca viu antes. O gráfico abaixo ilustra exatamente esse comportamento:
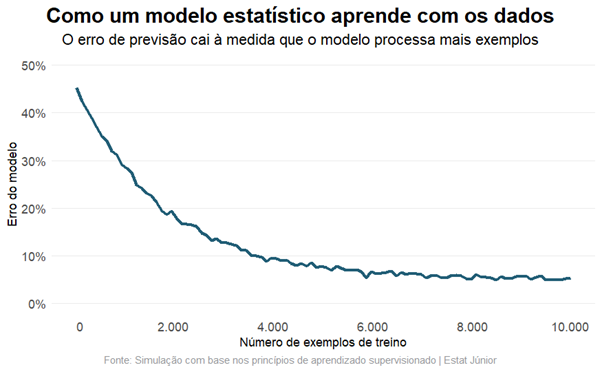
Observe que o erro cai de forma acentuada nos primeiros exemplos e vai se estabilizando conforme o volume de dados cresce. Esse comportamento é universal: vale para um modelo que prevê inadimplência, para um que recomenda produtos ou para um que detecta falhas em equipamentos industriais.
Vale destacar que há diferentes formas de estruturar esse aprendizado. Quando os exemplos históricos já vêm com a resposta correta, como uma transação marcada como fraude ou não, ou um cliente classificado como ativo ou em risco de cancelamento, o modelo aprende por supervisão, ajustando suas previsões com base no erro em relação à resposta conhecida. Quando os dados não têm rótulo e o objetivo é descobrir estruturas ocultas, como grupos de clientes com comportamentos similares, o aprendizado é não supervisionado. Cada abordagem responde a um tipo diferente de pergunta de negócio.
O ponto central, independentemente da abordagem, é que nenhum modelo funciona bem sem dados de qualidade, sem uma pergunta bem formulada e sem alguém que entenda tanto da técnica quanto do problema que se quer resolver.
Como isso funciona na prática?
Entender o conceito é um passo. O mais relevante para qualquer empresa, porém, é a pergunta seguinte: onde modelos estatísticos estão gerando retorno concreto?
A resposta é mais ampla do que parece. Segundo levantamento da McKinsey, as funções empresariais que mais concentram a adoção de IA são exatamente aquelas com maior impacto direto no resultado financeiro — marketing e vendas, operações de serviço e desenvolvimento de produtos lideram a lista. Mas o que esses números representam na prática? Três aplicações ilustram bem como a modelagem estatística se traduz em resultado mensurável.
- Detecção de fraude no mercado financeiro
O setor financeiro é um dos ambientes mais hostis para decisões baseadas em regras fixas: os padrões de comportamento mudam constantemente, e qualquer sistema rígido demais vira rapidamente obsoleto. Modelos de Machine Learning resolvem esse problema aprendendo continuamente com novos dados, identificando transações suspeitas em milissegundos com base em dezenas de variáveis simultâneas — valor, localização, horário, padrão histórico do cliente, dispositivo utilizado. No Brasil, as perdas com fraude ultrapassaram R$10 bilhões em 2024, um número que coloca a detecção automatizada não como diferencial competitivo, mas como necessidade operacional.
- Otimização de operações e estoque
Fora do ambiente digital, a modelagem estatística também está presente em decisões operacionais que mobilizam volumes expressivos de capital. No varejo, modelos de previsão de demanda determinam quanto de cada produto manter em estoque por região e por período, reduzindo tanto o custo de excesso quanto o de ruptura. Na indústria, algoritmos de manutenção preditiva identificam padrões de desgaste em equipamentos antes que uma falha ocorra, evitando paradas não programadas que custam ordens de grandeza mais do que qualquer revisão preventiva. Em ambos os casos, o modelo não substitui a decisão humana: ele a qualifica, entregando uma estimativa fundamentada no lugar de uma intuição.
- Previsão de churn em empresas de serviço
Churn é o nome dado à perda de clientes — quando um consumidor cancela um contrato, encerra uma assinatura ou simplesmente deixa de comprar. Reter um cliente custa sistematicamente menos do que conquistar um novo, e o problema é que, sem modelagem estatística, identificar quais clientes estão prestes a sair é quase impossível antes que o fato já tenha acontecido.
Modelos supervisionados de previsão de churn resolvem exatamente isso: treinados com histórico de comportamento, uso do produto, frequência de contato e outros sinais, eles atribuem a cada cliente uma probabilidade de saída, permitindo que a empresa aja antes, e não depois. Modelos que combinam diferentes técnicas de aprendizado supervisionado chegam a índices de acerto acima de 85% na previsão de cancelamentos, transformando um problema reativo num processo proativo de retenção.
O fio condutor entre esses três exemplos é o mesmo: dados que a empresa já possui, transformados em previsões úteis por um modelo bem especificado. E é exatamente aí que mora o próximo desafio: precisamos saber o que fazer com esses dados.
Onde a maioria das empresas estão falhando?
Se modelos estatísticos já provaram seu valor em tantos contextos, por que uma parcela tão grande das empresas ainda não colhe resultados concretos? A resposta raramente está na tecnologia.
O gargalo mais comum é anterior a qualquer algoritmo: são os dados. Não a falta deles, uma vez que a maioria das empresas coleta mais informação do que consegue processar, mas a qualidade, a organização e a clareza sobre o que se quer descobrir com eles. O crescimento do volume global de dados ajuda a ilustrar a dimensão desse problema:
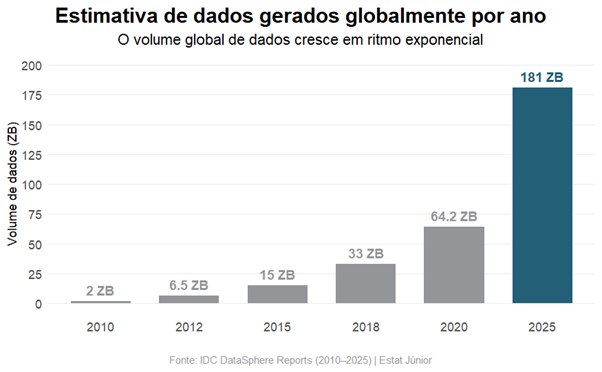
Observe como o volume de dados cresceu de forma acelerada ao longo dos anos. Em 2025, a estimativa da IDC aponta para 181 zettabytes gerados globalmente (equivalente a 181 trilhões de gigabytes) — um volume impossível de ser interpretado manualmente por equipes humanas. Nesse cenário, técnicas de modelagem estatística deixam de ser apenas ferramentas analíticas e passam a ser mecanismos necessários para transformar excesso de informação em decisões utilizáveis.
Um modelo treinado com dados inconsistentes, mal estruturados ou sem representatividade vai produzir previsões igualmente inconsistentes, com uma diferença importante em relação ao erro humano: ele vai errar em escala, com aparência de precisão e sem que ninguém necessariamente perceba.
Há também um segundo problema, mais sutil. Implementar Machine Learning sem uma pergunta de negócio bem definida é como contratar um especialista sem saber qual problema ele vai resolver. O modelo pode ser tecnicamente impecável e ainda assim inútil, se o que ele aprendeu a prever não tem conexão direta com uma decisão que a empresa precisa tomar. Não é raro ver projetos de modelagem que chegam a uma conclusão estatisticamente válida mas operacionalmente irrelevante — e que por isso nunca saem do papel.
Esse ponto é confirmado pelos números. Segundo dados de mercado, 70% das implementações de Machine Learning conduzidas sem orientação especializada falham em atingir os objetivos propostos. Não por falta de poder computacional ou de algoritmos sofisticados, mas por falhas nas etapas anteriores: definição do problema, curadoria dos dados e tradução do resultado estatístico em ação concreta.
O que separa as organizações que extraem valor real das que ficam presas em projetos-piloto intermináveis não é o acesso à tecnologia — essa barreira caiu muito nos últimos anos. É a capacidade de conectar o rigor técnico da modelagem à realidade do negócio: entender o que os dados podem e não podem responder, escolher o modelo certo para cada pergunta e transformar uma previsão em decisão.
Conclusão
A pergunta que mais aparece quando o assunto é Machine Learning não é técnica, mas estratégica: por onde começar?
A resposta, na maioria dos casos, é mais simples do que parece. Toda empresa que coleta dados já tem o ingrediente principal. O que falta, quase sempre, não é tecnologia nem infraestrutura: é saber formular a pergunta certa e ter quem saiba construir o modelo que a responde.
Um bom modelo de churn não exige um data center próprio. Uma previsão de demanda eficiente não depende de um time de cem pessoas. Depende de método, de dados bem organizados e de alguém que entenda tanto de estatística quanto do problema em questão.
É exatamente esse o trabalho da Estat Júnior: desenvolver soluções de modelagem estatística sob medida, conectando o rigor técnico à realidade de cada negócio. Se você tem dados e uma pergunta que ainda não tem resposta, nós te ajudamos a encontrá-la.
Assim como um modelo estatístico, aprenda com o passado e use seus dados para planejar seu futuro: mais seguro, mais inteligente e mais brilhante!
Autor: Pedro da Costa Lacerda