

A linguagem R é uma linguagem de programação muito utilizada entre os analistas de dados. É considerada uma das melhores linguagens para manipulação, análise e visualização de dados.
Na Estat Júnior, utilizamos muito essa linguagem na grande maioria dos nossos projetos. Neste texto, iremos reunir vários conceitos já tratados aqui no blog, em textos anteriores, e mostraremos na prática uma análise realizada em R, em um case realizado internamente aqui na empresa.
Para isso, foi utilizado um banco de dados disponível no site Kaggle: Childlessness Survey | Kaggle.
Nesse case, as principais premissas eram:
- Realizar uma limpeza no banco de dados;
- Calcular estatísticas sumárias para as variáveis consideradas importantes a serem analisadas;
- Fazer uma boa análise descritiva, com gráficos e tabelas.
Do banco de dados no Kaggle, foram coletadas respostas de 30 perguntas para rastrear atitudes sociais em relação a não ter filhos.
Para o case, foram realizados três relatórios diferentes (havia 3 grupos), cada um com um objetivo específico em relação a análise de variáveis. Em cada relatório, foram incluídas análises descritivas, com gráficos e tabelas sobre os respondentes da pesquisa e as respostas obtidas. Aqui, mostraremos como o R foi utilizado, de uma forma geral, para construir a análise e, para tanto, apresentaremos alguns exemplos escolhidos desses relatórios para ilustrar e facilitar o entendimento sobre como a análise foi feita. Para a montagem do relatório, o site overleaf foi utilizado.
Inicialmente, realizamos uma visão geral das informações, com dados sumários das respostas, divididas pelas categorias das perguntas realizadas. Isso pode ser visto na tabela abaixo, construída pelos nossos membros em um dos relatórios produzidos.

Os seguintes comandos auxiliaram na obtenção dos dados pelo R, para a montagem da tabela no Overleaf. Um exemplo das questões sobre Finanças:
Para cada questão:
- financialQ1 = b %>%
group_by(Q1) %>%
summarise(Frequencia = n()) %>% rename(‘questao’ = Q1)
Para agrupar por temas:
- financialQ1 %>% bind_rows(financialQ2) %>%
bind_rows(financialQ3) %>%
bind_rows(financialQ4) %>%
bind_rows(financialQ5) %>%
bind_rows(financialQ6) %>%
group_by(questao) %>%
summarise(Frequencia = sum(Frequencia))
Para complementar a tabela, foram escritas as seguintes considerações:
“…categoria por categoria, 47% das pessoas que responderam à pesquisa concordam ou concordam totalmente que as perguntas relacionadas à temas financeiros têm impacto na decisão de ter filhos, 62% nas questões que envolvem escolhas pessoais, 41% em influências externas e 10% em saúde, essa última sendo significativamente inferior às demais.
[…] Vale lembrar que as respostas da pergunta 11 (relacionada a escolhas pessoais) não foram contabilizadas nessa tabela pois apresentavam resposta binária, isto é, sim ou não, e nesse sentido não seria relevante para essa análise.”
Juntamente a isso, foi mostrado o perfil geral dos respondentes, com gráficos e tabelas expondo as principais características, como idades, status de emprego, status de relacionamento, gêneros e se já possuem filhos ou não. Por exemplo, a figura abaixo é um dos gráficos criados para ilustrar a distribuição da amostra segundo a idade:

Para elaborar esse gráfico, utilizamos o seguinte comando:
datageral %>% ggplot(aes(x = Age))+
geom_histogram(breaks = seq(15,65,by = 5), color = ‘black’,fill = ‘#235F77’)+
xlim(14,66)+
labs(x = “Idade”,y=”Frequência”)+
theme_bw()
Tendo “datageral” como a variável que possui os dados referentes às idades
Posteriormente, foram feitas análises descritivas dividindo os diferentes temas das perguntas.
Dois modelos foram apresentados. No primeiro, houve pequenas observações com estatísticas sumárias para cada uma das perguntas, da seguinte forma:

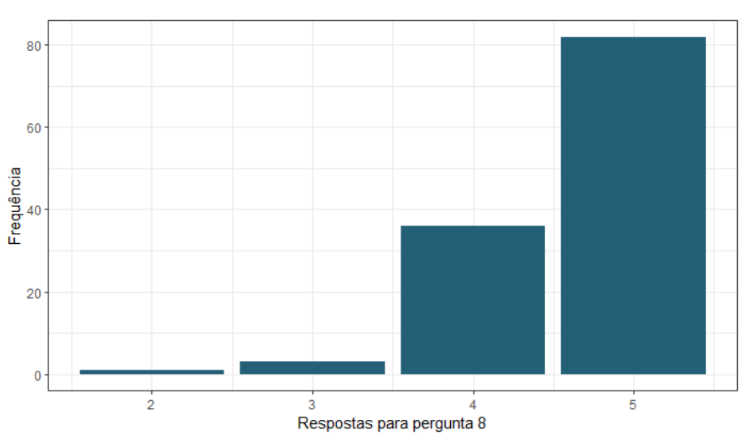
Para ilustrar melhor as informações da tabela, também foram realizados gráficos com a frequência de resposta de cada pergunta.
No segundo modelo, temos informações expostas em gráficos, sendo um para cada tema de pergunta, separados por gênero. Exemplo:

Para a construção dos gráficos, foi utilizado o pacote “ggplot2”. Sua documentação pode ser vista clicando aqui.
Para exemplificar a construção, segue o código para o gráfico anterior, sendo “generos3” a variável em que se encontra os dados sobre as questões 21-30:
ggplot(generos3)+
geom_col(aes(x = Questões,y = Médias, fill = Gêneros), position = “dodge”)+
theme(axis.text = element_text(size = 12, face = “bold”), axis.title = element_text(size = 15), plot.title = element_text(size = 20, face = “bold”), plot.subtitle = element_text(size = 16), legend.text = element_text(size = 10, face = “bold”), legend.title = element_text(size = 12, face = “bold”))+
labs(title = “Média das Respostas das Questões sobre Saúde”, subtitle = “Média das Respostas das Questões de 21 a 30, separadas por gênero masculino e feminino”)
Para finalizar, foram feitas considerações finais, resumindo a análise em poucas palavras e tirando conclusões sobre os gráficos e tabelas realizados.
Os relatórios foram construídos pelos membros:
Isabella da Silva, Vitor Rizzo, Rafael Suetsugu, Rafael Maniezo, Helena Neder, Marcos Viotto, Décio Miranda, Lucas Gomes, Lucas Kist e Thiago Makoto.
Autor: Rafael Maniezo
